爱拼长图:解构AIGC时代下的视觉内容创作新范式
1.引言:不止于拼图,我们用AI重塑视觉创意
在移动互联网的视觉化浪潮中,图片处理应用层出不穷。“爱拼长图”从诞生之初,就旨在突破传统工具的边界。我们不满足于仅仅提供一个将多张图片简单拼接的功能,我们的愿景是——借助AIGC(AI Generated Content)的革命性力量,为每一位用户提供一个集智能创作、专业级修复与趣味性玩法于一体的视觉内容创作平台。
当用户将一组充满回忆的照片导入“爱拼长图”,我们希望提供的不仅是一次拼接,而是一次“升华”。无论是将模糊的旧照一键修复至高清,为平淡的人像智能补上专业级的伦勃朗光,还是将静态的毕业合影转化为一段生动的、带有微表情的动态视频,这些看似“魔法”般的效果,背后是团队对前沿AI技术的深入研究、审慎选型和极致的工程优化。
这篇技术博客,将带您深入“爱拼长图”的引擎室,解构我们如何在一个小小的APP中,融合并驾驭图像拼接、AI修复、人脸技术、智能打光乃至图生视频等多种尖端技术。我们将分享我们的技术架构、对核心开源项目的选择与思考,并重点展示我们在模型优化、移动端适配和创新性功能组合上的独特实践。

2.技术架构概览:端云协同,鱼与熊掌亦可兼得
在AI功能日益强大的今天,算力已成为决定用户体验的关键瓶颈。为了在强大的AI效果与流畅的移动端体验之间取得最佳平衡,“爱拼长图”从设计之初就确立了“端云协同、混合部署”的核心架构思想。
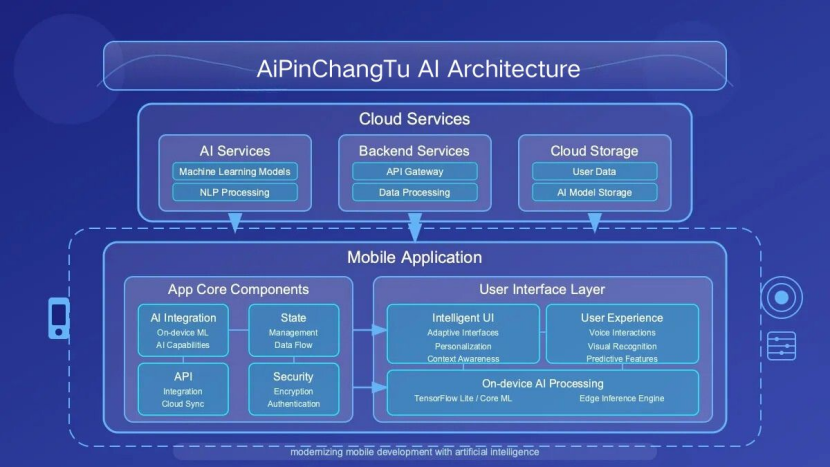
我们的技术栈可以概括为:
云端(Cloud-Side)效果与创新的孵化器:
- 核心任务:负责执行所有计算密集型、模型体积庞大的前沿AIGC任务。
- 技术栈:
- 计算框架:全面拥抱PyTorch,利用其灵活性和庞大的研究社区生态进行模型训练、微调和推理。
- GPU加速:基于NVIDIA CUDA和CuPy库进行深度优化,最大化服务器端图像处理和模型推理的吞吐量。
- 核心功能:高质量图像增强 (Real-ESRGAN)、智能重打光 (IC-Light)、图生视频 (Stable Diffusion)、通用换脸 (IpAdapter,PuLID) 等旗舰功能均有支持。
移动端(On-Device)实时交互与隐私的守护者:
- 核心任务:负责高频、低延迟的实时交互功能,并处理用户隐私敏感数据。
- 核心功能:图像基础滤镜、轻量级美化、UI交互的实时预览等。
这种端云协同的架构,让我们既能毫不妥协地追逐SOTA(State-of-the-Art)模型的最佳效果,又能确保APP的基础操作如丝般顺滑,将宝贵的手机计算资源用在刀刃上。
3.核心技术深度解析:站在巨人的肩膀上
“爱拼长图”的众多功能,都构建于当今最优秀的开源项目之上。我们的核心工作在于精准地“选”,深入地“改”,并创造性地“融”。
3.1拼图:布局随性,无限拓展
- 经典与现代的结合:我们的拼接引擎基础层,依然依赖于计算机视觉的“标准答案”——OpenCV。我们利用其稳定、高效的特性,实现了任意数量拼接后再进行高保真压缩。
- 无缝融合的艺术:为了消除拼接缝,我们没有满足于简单的线性融合(Feathering)。针对不同场景,我们实现了动态切换的融合策略:对于光照一致的图片,采用性能更优的多频段融合(Multi-band Blending);而对于光照差异大的图片,则启用效果更自然的泊松融合(Poisson Blending),确保拼接边缘的天衣无缝。
- AI驱动的布局:传统的模板式拼图布局呆板且缺乏新意。我们正在积极探索AI布局算法,通过可微分的概率树生成器,让AI学习和创造出更具美感和动态感的拼图布局方案。
3.2 AI修图技术栈:化腐朽为神奇
统一的修复框架:我们的AI修图功能,统一构建在BasicSR这个强大的开源图像复原工具箱之上。它集成了众多SOTA模型,为我们提供了一个统一的训练和测试平台。
核心模型矩阵:
- 一键变高清 (超分辨率):核心采用Real-ESRGAN。它针对真实世界的复杂退化(模糊、噪声、压缩伪影)进行优化,效果远超传统放大算法。
- 极致去噪与锐化:SwinIR是我们的首选。其强大的Swin Transformer架构能捕捉全局图像信息,在去除噪声和恢复细节上表现卓越。对于需要快速处理的场景,我们也会使用更轻量的DnCNN模型。
- 人脸修复:专门针对人脸的修复和增强,我们集成了PMRF,它能在提升清晰度的同时,保持人脸的身份特征和自然质感。
- 未来的探索(扩散模型):我们正密切关注Diffusion Model和AR Model在图像修复领域的应用,如ResShift等项目,其在生成逼真细节方面的潜力巨大。
3.3 AI换脸技术:趣味性与责任并重
通用化、低门槛的实现:为了让用户能“一键换脸”,我们摒弃了需要针对特定人物进行漫长训练的 `DeepFaceLab` 式方案,转而采用了更先进的“One-Shot”通用换脸框架。
核心技术选型:
- IpAdapter:是我们实现任意人脸交换的基础。它无需预训练,能够用一个统一模型处理所有换脸请求,完美契合APP快速响应的需求。
- PuLID:作为IpAdapter的有力补充,它在保持身份一致性和处理视频动态方面表现更佳,是提升换脸视频质量的关键。
3.4 AI打光技术:光影的重塑者
革命性的2D重打光:我们率先集成了2024年的现象级项目——IC-Light。它允许我们为用户的照片提供“电影级”的重打光服务。用户只需选择预设的光照模板(如“午后窗光”、“霓虹之夜”),IC-Light就能在云端为整张图片施加统一、和谐、物理真实的全新光照。
3.5 图转视频技术:让回忆流动
让静态照片“活”起来:这是AIGC时代最激动人心的功能之一。
核心技术驱动:
- Stable Video Diffusion (SVD):由Stability AI官方出品,是实现“照片会说话/动”功能的主力。用户上传一张图片,SVD便能生成一段视角、动态自然流畅的短视频。
- 通义万相:它的“即插即用”特性是我们的最爱。我们可以将为“爱拼长图”定制的各种LORA艺术风格模型,与万相结合,直接生成具有该独特风格的动态视频,创造出无穷的玩法。
- 从图像帧到视频文件:AI模型生成的只是一系列PNG图片,我们将这些帧序列通过
FFmpeg(由MoviePy封装)在服务器后端进行高效编码,最终合成为用户可以播放和分享的MP4视频文件。
4. 独立优化与创新亮点:不止是“拿来主义”
对开源技术的深入理解和二次创新,是“爱拼长图”技术团队的核心价值所在。
4.1 “不止于用”,我们训练自己的LORA
我们不满足于只使用社区现成的LORA模型。我们构建了自己的一套基于QLoRA的轻量化微调管线。
QLoRA的应用:通过引入4-bit量化,我们成功地在有限的云端资源上,微调了像Flux-Schnell这样的百亿参数级大模型。这使得我们能够:
- 创造独家艺术风格:训练“爱拼长图”专属的艺术风格LORA,形成产品独特的视觉护城河。
- 实现“虚拟代言人”:训练特定人物的LORA,用于APP内的教程引导、活动宣传等场景。
灵活的“插件式”体验:用户在创作时,可以将我们提供的多种风格LORA、人物LORA进行权重叠加,像调配鸡尾酒一样,混合出自己独一无二的视觉效果。
4.2 创新的技术组合应用
我们认为,单一技术的强大远不如技术组合带来的“化学反应”更具吸引力。
- 拼图` x `AI打光` = `全局光照统一`:用户完成一张拼图后,往往会因为原始照片光照不一而显得突兀。我们创新地将拼接好的成品图作为一个整体,送入 `IC-Light` 模型,一键应用一个全局统一的光照效果(如“清晨的柔光”),让整个作品看起来浑然天成。
- `拼图` x `图生视频` = `动态艺术作品`:这是我们的旗舰创新。用户完成一幅“梵高”风格的拼图后,可以进一步选择“动态化”。我们会将这幅拼图送入结合了梵高风格LORA的 `wan2.1` 模型,生成一段星空在旋转、麦田在摇曳的动态视频,作品的价值感和分享欲瞬间拉满。
5. 技术挑战与解决方案
在探索AIGC的道路上,我们遇到了诸多挑战:
挑战1:生成内容的“失控”与“不像”问题。
- 解决方案:我们通过增强数据集和精细化微调来解决。例如,在训练人物LORA时,我们会加入更多不同角度、不同表情的数据;在换脸后,我们会通过 `ArcFace` 计算身份相似度,如果低于阈值则进行调整或提示用户更换角度。
挑战2:视频生成的时间一致性问题。
- 解决方案:我们在 `wan2.1` 的基础上,增加了 **帧间光流约束** 和 **注意力机制平滑** 的后处理步骤,以减少视频的闪烁和抖动。
挑战3:伦理与安全风险。
- 解决方案:我们对所有AIGC功能,特别是换脸,都建立了严格的内容审查机制。在服务器端,我们部署了用于识别公众人物和不当内容的分类模型。同时,我们正在研发为所有AI生成内容添加不可见数字水印的技术,以确保内容的可追溯性。
6. 未来技术发展规划
AIGC技术日新月异,我们将持续保持技术嗅觉的敏锐。
- 拥抱更强的视频模型:我们正密切跟进通义万相,混元等开源项目的进展,并计划在未来引入更强大的长视频、高保真视频生成能力。
- 追求更自由的控制:当前的生成内容在可控性上仍有不足。我们的下一个研发重点是实现“可控生成”。例如,让用户用笔刷涂抹来指定画面中需要“动起来”的区域,或者通过绘制运动轨迹来控制物体的移动路径。
- 探索3D与3DGS:我们相信3D技术是提升真实感的关键。我们计划探索从2D图像重建3D模型(特别是人脸),并引入3DGs (3D Gaussian Splatting)技术,以实现更自由的视角变换和更符合物理规律的重打光效果。
7. 总结
“爱拼长图”的技术哲学,是在拥抱开源社区的巨大力量与坚持独立自主的深度优化之间,寻找最佳的平衡点。我们相信,决定一款应用成败的,不只是你用了多么前沿的技术,更是你如何将这些技术进行创造性的组合,并通过极致的工程化能力,将其转化为稳定、流畅、富有惊喜感的用户体验。
我们的探索才刚刚开始。我们期待与所有技术同道一起,在AIGC的浪潮之巅,共同塑造视觉内容创作的未来。


- The Square-Round Face Revolution: Why One Hairstyle Teaser Has the Internet Camping for Answers
- 方圓臉本命髮型引爆焦慮?網美教學未出先紅,留言區淪為「認親」與「催更」戰場
- AI Beauty Meets Cold Brew: A Digital Tea Ritual Sparks Heated Debate on Tradition and Tummy Aches
- AI美女泡冷茶掀戰火?網民神回覆揭開「腸胃保衛戰」與「暗黑萃取學」
- The Art of Culinary Restraint: Why Novice Chefs Should Embrace Strategic Laziness
- 新手下廚別太勤快?魏老爸「懶惰烹飪法」引爆廚房共鳴
- Digital Talismans at 2 AM: When Health Warnings Meet Sleepless Despair
- 深夜科普變「賽博祈福」:熬夜猝死警示下的集體焦慮與無奈
- The American Front Spike: When Viral Hairstyles Meet Exaggerated Reality
- 「美式前刺」成流量密碼?網友戲稱排卵期濾鏡全開,東北豪爽美學引爆審美焦慮

全部评论